[0325 복습] 데이터 분석 표현_스트림릿 title, caption, header, markdown, code, latex, write, metric, selectbox ..etc
데이터 분석 표현_스트림릿
anaconda prompt에서 바로 jupyter lab 입력
CH1. 스트림릿 개요
스트림릿 이해
: 빠름, 웹 기반의 어플리케이션, 공유가 원활, 인터랙티브(상호 작용)
스트림릿 설치 및 사전 세팅
: pip list로 설치된 모든 모듈 확인
: pip install streamlit == 1.30.0 로 1.30.0 버전으로 streamlit 설치
: streamlit hello 명령어 입력 후 Email: 이메일 주소 입력
: 주피터랩에서 Settings - Terminal Theme - Dark로 변경
CH2. 기본 elements
Text elements
- 해당 파이썬 파일을 실행하려면 File - New - Terminal 접속 후 streamlit run 폴더명\파일명.py 실행
- 코드 추가 후 재 실행하려면 브라우저에서 새로고침 or R (run) 입력
** 같은 py 파일이 아니라면 Ctrl + C 로 중단 후 실행 해야 함!
- title / caption / header / subheader / markdown / divider
import streamlit as st
import pandas as pd
st.title('제일 큰 타이틀')
st.caption('캡션 달기')
st.header('헤더: 두 번째로 큰 글씨')
st.subheader('서브헤더: 두 번째로 큰 글씨')
st.markdown('# 마크다운 1')
st.markdown('## 마크다운 2')
st.markdown('### 마크다운 3')
st.markdown('**_마크다운 진하게&기울임_**')
st.markdown('- 마크다운 글 머리\n'
' - 마크다운') # 이런 식으로 - 앞 뒤에 공백 추가하면, 들여쓰기도 가능함!
st.divider()
- code / latex / write
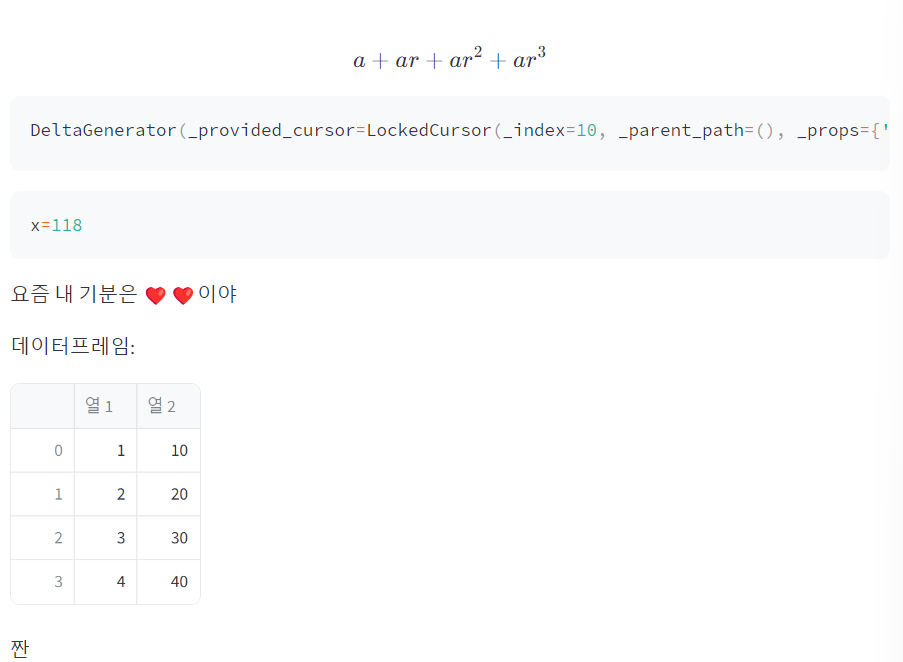
# code: 복사할 수 있음, latex: 수학식 표현 가능
st.code(st.latex('a + ar + ar^2 + ar^3'))
# 만능 write: string, data_frame, chart, grapth, latex등의 objects를 App에 출력 가능
st.write('요즘 내 기분은 ❤️❤️이야')
# write을 통해 df를 만들기
df = pd.DataFrame({'열 1': [1,2,3,4], '열 2': [10, 20, 30, 40]})
st.write('데이터프레임: ', df, '짠')
Media elements
- image / audio / video
st.image('이미지 경로\파일명')
st.audio('오디오 경로\파일명')
st.video('비디오 경로\파일명')
Data display elements
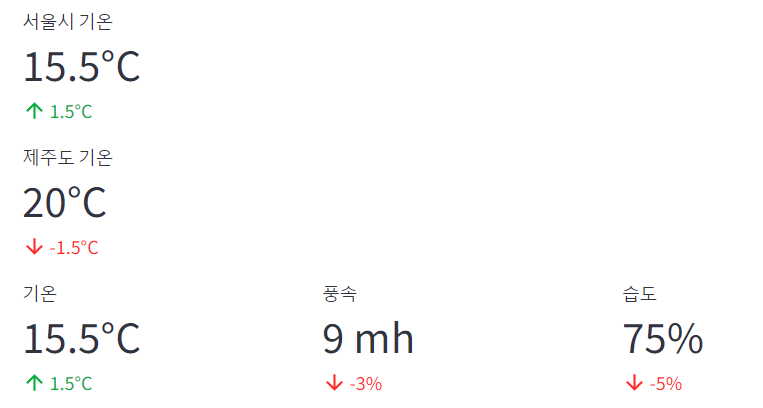
- metric 측정항목은 타이틀, 값, 변동 값을 보여줌
- 주로 기온, 풍속, 습도 등 변동 값을 함께 보여주는 경우에 사용
- label = / value = / delta = 는 생략 가능!
- st.columns(열 개수): 열을 여러 개로 나누어 각각 내용을 보여줌
st.metric(label='서울시 기온', value='15.5°C', delta ='1.5°C')
st.metric(label='제주도 기온', value='20°C', delta ='-1.5°C')
col1, col2, col3 = st.columns(3) #st.columns([2, 1, 1]) 작성하면 각 열 별 너비를 지정
col1.metric('기온', '15.5°C', '1.5°C')
col2.metric('풍속', '9 mh', '-3%')
col3.metric('습도', '75%', '-5%')
- dataframe(df), write(df): 데이터 프레임을 보여줌, 10개 행을 기준으로 스크롤 구분
- 열 크기 조정, 열 정렬(열 이름 클릭), 테이블 확대 모두 가능!
** 판다스에서는 DataFrame(대문자), 스트림릿에서는 dataframe(소문자)로 주의!
- table(df)은 고정 형태의 테이블로 열 크기 조정, 열 정렬, 테이블 확대 불가능함
Input Widgets
- radio / button / slider / widget
if st.button('인사'):
st.write('안녕')
else:
st.write('잘가')
food = st.radio('좋아하는 음식을 선택해주세요',
('피자', '떡볶이', '삼겹살'))
if food == '피자':
st.write('피자 맛있죠')
elif food == 'SF':
st.write('저도 떡볶이 좋아합니다')
else:
st.write('삼겹살에는 소주죠')

- checkbox / toggle / selectbox / multiselect
# 체크박스에 체크하면 이모지 나타남
agree = st.checkbox('인정합니다')
if agree:
st.write('🫰'*10)
# 선택지가 세 개
option = st.selectbox('어디로 연락드릴까요?',
('이메일', '휴대전화', '사무실'))
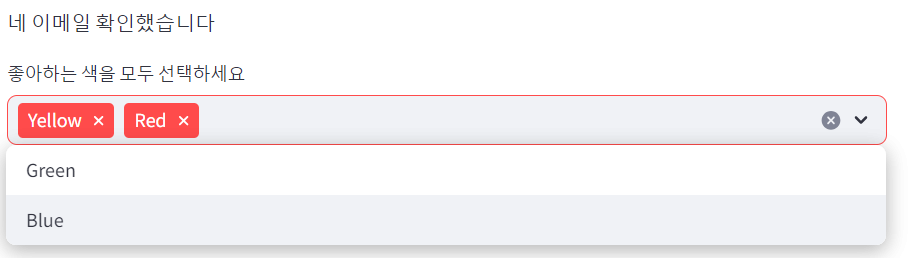
st.write('네 ',option, ' 확인했습니다')
# 모든 선택지는 첫 번째 리스트 요소, 이미 선택된 옵션은 두 번째 리스트 요소
options = st.multiselect('좋아하는 색을 모두 선택하세요',
['Green', 'Yellow', 'Red', 'Blue'],
['Yellow', 'Red'])
st.write('선호 색상:', ', '.join(options))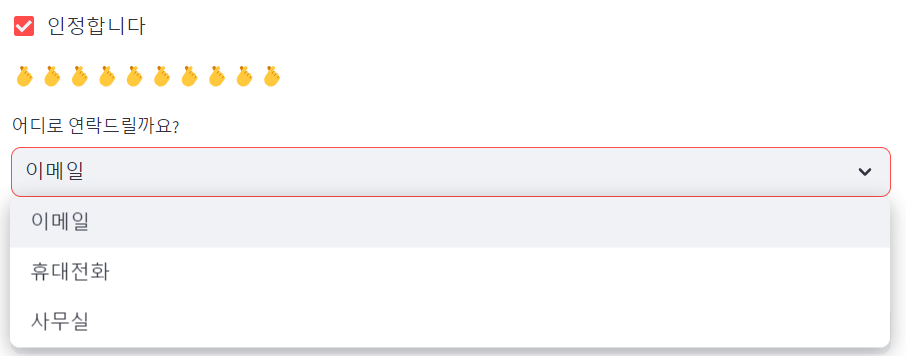
- text_input / number_input / date_input (텍스트, 숫자, 날짜를 입력 받는 위젯)
title = st.text_input('최애 영화를 입력하세요',
'어바웃타임') # 최초 입력값 설정
number = st.number_input('숫자를 입력하세요(1-20)',
min_value=1, max_value=20, value=5, step=1) # 최소값, 최대값, 최초 입력값, 증분값
from datetime import datetime # datetime 라이브러리
ymd = st.date_input('당신의 생일은?',
datetime(2000,1,18)) # 최초 입력값

- slider
age = st.slider('나이', 0, 100, 25) # 입력 가능 범위 (0, 130), 최초 입력값
values = st.slider('값 구간을 선택하세요',
0.0, 100.0, (20.0, 55.0)) # 입력 가능 범위 (0, 100), 최초 세팅 범위 (20, 55)
slider_date = st.slider('날짜 구간을 선택하세요 ',
min_value = datetime(2022, 1, 1),
max_value = datetime(2024, 12, 31),
value = (datetime(2023, 1,1), datetime(2024,1,1)),
format = 'YY/MM/DD')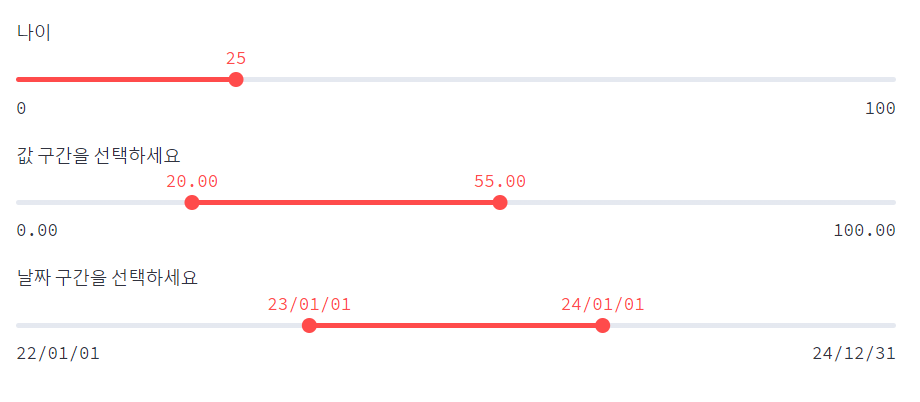
- slider 날짜구간으로 데이터 읽어오기
- slider_date[0]이 구간 시작값, slider_date[1]이 구간 끝값
→ 인덱싱이 0,1 두개 밖에 없음! why? 구간 시작 - 끝값은 어차피 하나니까요~
df = pd.read_csv('파일명', encoding='cp949') # 인코딩 오류시 UTF-8
st.write('날짜 필드 형식: ', df['날짜'].dtypes)
df['날짜'] = pd.to_datetime(df['날짜'], format = '%Y-%m-%d') # datetime으로 변환
# slider_date의 구간 날짜 확인하기
st.write('slider_date[0]: ', slider_date[0], 'slider_date[1]: ', slider_date[1])
# slider_date의 선택된 시작, 종료 날짜를 start_date, end_date에 저장하기
start_date = slider_date[0]
end_date = slider_date[1]
# slider 날짜 구간으로 df를 읽어서 새 sel_df 으로 저장하고 확인하기
sel_df = df.loc[df['날짜'].between(start_date, end_date)]
st.dataframe(sel_df)
Layouts & Containers
- sidebar / selectbox
with st.sidebar:
st.header('1. 사이드바')
add_selectbox = st.sidebar.selectbox('연락 방법을 알려주세용',
('이메일', '휴대전화', '사무실'))
if add_selectbox == 'Email':
st.sidebar.title('📧')
elif add_selectbox == 'Mobile phone':
st.sidebar.title('📱')
else:
st.sidebar.title('☎︎')
- tab: 각 탭별로 나누어 이미지 보여줌
tab1, tab2, tab3 = st.tabs(['초록', '노랑', '연두'])
with tab1:
st.caption('초록')
st.image('C:\Users\User\Desktop\초록.png')
with tab2:
st.caption('노랑')
st.image('C:\Users\User\Desktop\노랑.jfif')
with tab3:
st.caption('연두')
st.image('C:\Users\User\Desktop\연두.png')
- multipage: 멀티페이지를 생성해 각 페이지에 기록될 내용을 함수로 선언
def main_page():
st.title('메인 페이지 🎈')
st.sidebar.title('사이드 메인 🎈')
def page2():
st.title('페이지 2 ❄️')
st.sidebar.title('사이드 2 ❄️')
def page3():
st.title('페이지 3 🎉')
st.sidebar.title('사이드 3 🎉')
# 딕셔너리 선언 { ‘selectbox항목’ : ‘페이지명’}
page_names_to_funcs = {'메인 페이지': main_page, '페이지 2': page2, '페이지 3': page3}
# 사이드 바에서 selectbox 선언 & 선택 결과 저장
selected_page = st.sidebar.selectbox('페이지를 선택하세요', page_names_to_funcs.keys())
# 해당 페이지 부르기
page_names_to_funcs[selected_page]()
CH3. Chart elements
데이터 다루기
- 원본 데이터프레임에서 필요한 조건에 따라 데이터 전처리 후 차트 그리기- melt 함수(데이터 재구조화)- pd.melt (df, id_vars=['ID 변수'], var_name='기존 열 이름1', value_name= '값으로 구성된 열 이름2')
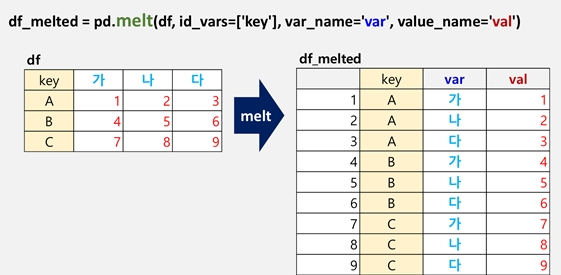
df_line_melted = pd.melt(df, id_vars=['호선'], var_name='시간', value_name='인원수')
st.dataframe(df_line_melted)
df_line_groupby = df_line_melted.groupby(['호선', '시간'], as_index=False)['인원수'].sum()
st.dataframe(df_line_groupby)
- pivot: 피벗 테이블
df.pivot(index='열 이름', columns='열 이름', values='열 이름')
index : 인덱스로 사용될 열
columns : 열로 사용될 열
values : 값으로 입력될 열
Streamlit Simple chart
- st.line_chart(chart_data): 선 그래프
- st.bar_chart(chart_data): 누적 바 그래프
- st.area_chart(chart_data): 그래프의 영역이 채워진 채로 나타남
Altair chart
- 데이터 컬럼과 x축, y축, 색상, 크기 등 encoding channel 간의 연결 정의
- 차트에 값 표시가 가능하며, 데이터 설명도 표시할 수 있다
- 라이브러리 불러오기: import altair as alt
chart = alt.Chart(df, title= '제목').mark_line().encode(x='x축 열이름', y='y축 열이름', color='범례', strokeDash = '범례').properties(width=숫자, height=숫자)
st.altair_chart(chart, use_container_width=True) #가로로 화면에 채워줌
- mark_line() 을 mark_bar()로 바꿔주면 누적 막대 그래프
mark_circle()로 바꿔주면 산점도가 출력됨!
- mark_text(): 막대에 값을 표시하는 옵션 → 이때 숫자는 값의 누적 막대가 아닌 값의 실제 위치에 표시됨
Plotly chart
- 범례 선택으로 그래프 모양 변경, 데이터 설명 표시
- 라이브러리 불러오기: import plotly.express as px
fig = px.pie(df, names='x축 열 이름', values ='범주 값 열 이름', title='그래프 제목', hole=.3) #hole은 도넛 구멍의 크기
fig.update_traces(textposition='inside', textinfo='percent+label+value')
fig.update_layout(font=dict(size=14))
# fig.update(layout_showlegend=False) # 범례 표시 제거
st.plotly_chart(fig)
- 누적 세로 막대 그래프 작성
fig = px.bar(medal, x='x축 이름', y =['범주 값 열 이름1', '범주 값 열 이름2', '범주 값 열 이름3'],
text_auto=True, title='그래프 제목') #### text_auto=True 값 표시 여부
fig.update_layout(width=800, height=600) # 그래프 크기 조절
fig.update_traces(textangle=0) # 그래프 안의 텍스트가 바로 쓰여지게 설정
st.plotly_chart(fig)