-
[0319 복습] 웹 크롤링_동적 페이지, REST API, HTML, CCS-SelectorKT 에이블스쿨 복습 2024. 3. 19. 19:56
웹 크롤링(Web Crawling) (2)
크롤링 심화
- 파이썬 코드로 웹 서버에 데이터를 긁어오면 Was는 abuser로 판단해서 request를 차단
- request할 때 Client, header 영역에 user-agent라는 정보가 자동으로 전달됨
- user-agent: 컴퓨터가 윈도우인지, OS인지 접속한 브라우저 정보 들어있는 것!
**파이썬으로 불러오면 user-agent에 python이 들어가 있음 ! → 정상적인 request 보내지 말아야 겠다고 판단하는 것
** 이 경우 파이썬 코드로 데이터를 수집할 수 없음!
→ 회피 방법? request는 client쪽에서 만들어지는 data이기 때문에,
파이썬에서 코딩으로 user-agent 정보를 설정해서 서버로 보내는 것!크롤링 절차
- 기존대로 url을 가져오고, request > response 과정에서 403 에러가 발생 !
- url을 이용해서 request 했더니 403 에러 메시지를 서버에서 전달함!
- 아래 이미지는 에러일 때 response.text 결과값

- Was 입장에서 403 띄운 이유는 정확히 알 수 없음!
- 따로 설정하지 않으면 header의 user agent가 파이썬으로 들어감 → user agent확인 referer확인

import pandas as pd import requests url = '링크' # User-Agent, Referer을 헤더로 지정 headers = {'User-Agent': '개발자도구에서 복붙','Referer': '개발자도구에서 복붙',} response = requests.get(url, headers=headers) data = response.json()['data'] df = pd.DataFrame(data)[['가져올 열이름1','가져올 열이름2','가져올 열이름3' ]]- header 사이에 콤마를 쓰는 이유: 코드를 확인할 때 어떤 코드가 바뀌었는지를 알기 위함! (콤마를 찍어놓으면 콤마 바로 앞줄만 확인하면 됨!)
- referer: url1에서 url2로 이동함! 이때도 request가 일어남, referer라는 곳은 url1로 들어가서 request를 요청
→ 현재 보고 있는 사이트 이전에 보고 있던 (url1) 사이트가 무엇인지 확인할 수 있는 방법!
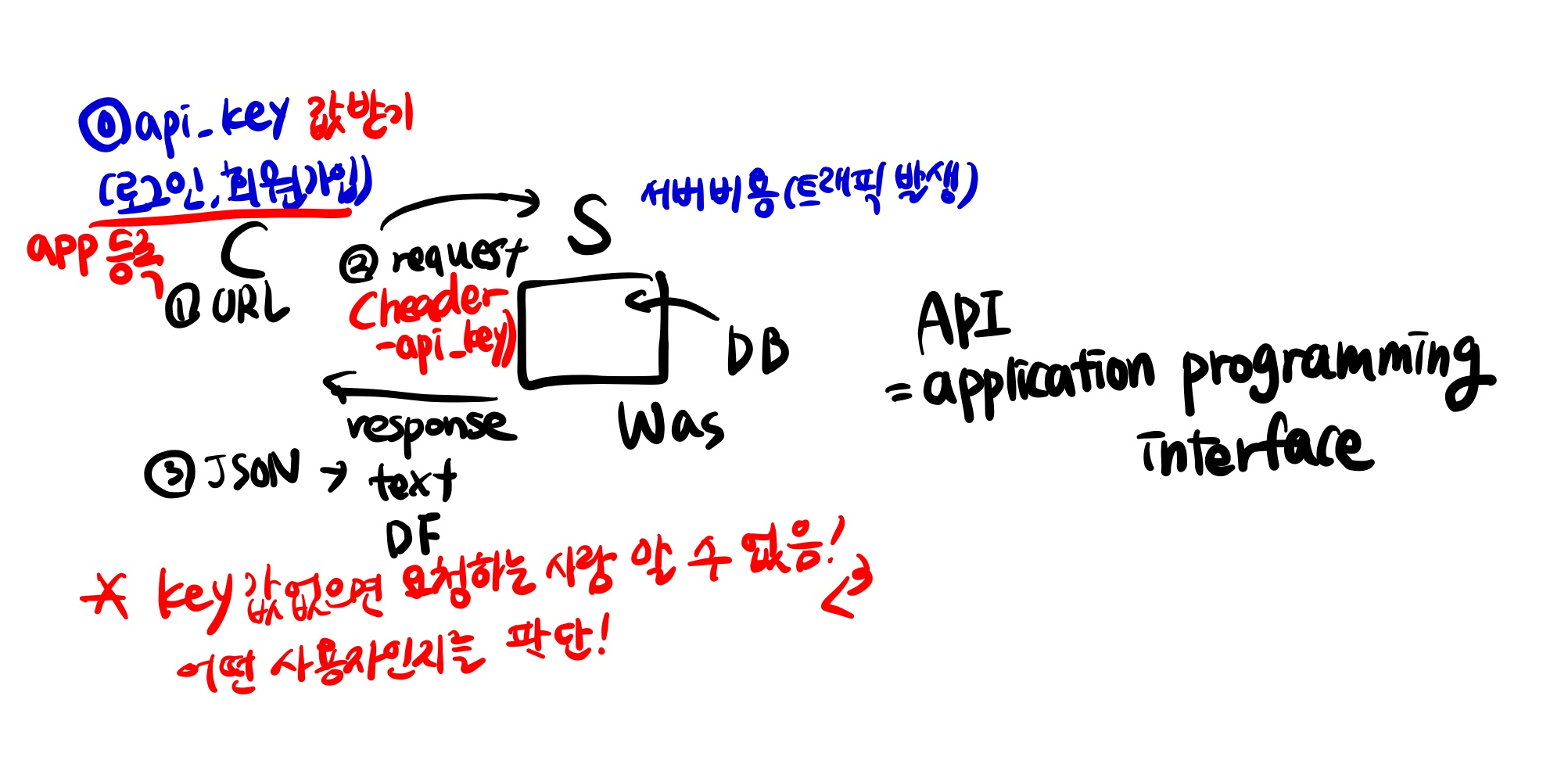
REST API
- kakao developers 접속 후 로그인
- 내 애플리케이션 > 애플리케이션 추가하기 > KT라는 새로운 앱 생성
- 문서 > KoGPT > REST API > 도큐먼트에 친절히 사용방법 설명되어 있음!
- 쿼리 파라미터를 확인: 필수 파라미터가 2개 prompt, max_tokens

- 아래는 다음 문장 만들기 코드!
# 1. document : url REST_API_KEY = 키 값 가져오기 (내 애플리케이션에서) url = '링크' prompt = '원자폭탄을 발명한 사람은' params = {'prompt': prompt, 'max_tokens' : 50(가져올 개수)} headers = {'Content-Type': 'application/json', 'Authorization': f'KakaoAK {REST_API_KEY}'} # 2. request(url, headers, params) > response(data): json(str) response = requests.post(url, json.dumps(params), headers=headers) response # 3. json(str) : text response.json()['generations'][0]['text'].strip()- jump.dumps: 파라미터에 한글이 있는 경우 인코딩하는 것
직방 매물 데이터 실습_매물 아이디로 매물 정보 가져오기
- 사이트 접속 > 원룸 > 망원동 검색 > 두번 검색하면 망원동 검색한 내용이 브라우저에 저장됨!
→ 개발자 도구에서 네트워크가 새로 뜨지 않음
- headers확인: payload 탭 확인하면 한글 깨진 내용 알 수 있음
https://meyerweb.com/eric/tools/dencoder/
URL Decoder/Encoder
meyerweb.com
→ 영어로 되어있는 것 한글로 디코딩
- geohash: wydjx 를 설정해줘서, response에 x,y에 위도 경도값이 나타남!
(특정 위치가 아니라 매물정보가 모인 영역 전체를 설명할 때 → geohash로 지리정보 시스템에서 사용함!)#%%~부분은 모듈 저장 %%writefile zigbang.py import pandas as pd # 모듈에 저장할 때는 새로 불러와야 함 import requests import geohash2 def oneroom(addr): url = f'{addr}포함된 링크' response = requests.get(url) data = response.json()['items'][0] #ㅇㅇ동에 대한 결과값이 여러개일 수도 있기 때문에 리스트로 출력됨, 가장 먼저 나오는 데이터를 가져오기 위해 인덱싱 [0] 해줌 lat, lng = data['lat'], data['lng'] # precision : 영역 범위 : 커질수록 영역이 작아짐 # 다른 동에 대한 검색도 파이썬에서 가능할 수 있도록 하기 위해 geohash값을 복붙이 아니라, # geohash 패키지를 사용해서 값을 가져오는 것! geohash = geohash2.encode(lat, lng, precision=5) url = f'{geohash}포함된 링크' response = requests.get(url) items = response.json()['items'] ids = [item['itemId'] for item in items] url = '리스트 링크' params = {'domain': 'zigbang', 'item_ids': ids} response = requests.post(url, params) items = response.json()['items'] df = pd.DataFrame(items) df = df[df['address1'].str.contains(addr)].reset_index(drop=True) columns = ['불러올 열 이름1', '불러올 열 이름2', '불러올 열 이름3'] return df[columns] %ls zigbang.py # 모듈 저장 확인HTML
HTML
- HTML: 웹 문서를 작성하는 마크업 언어
HTML 구성요소
- Document: 한 페이지를 나타내는 단위
- Element: 하나의 레이아웃을 나타내는 단위(시작태그, 끝태그, 텍스트로 구성)
**element는 계층적 구조를 가지고 있음, 시작태그와 끝태그의 결합
- Tag: 엘리먼트의 종류를 정의: 시작태그(속성값), 끝태그
- Attribute: 시작태그에서 태그의 특정 기능을 하는 값
- id: 웹 페이지에서 유일한 값
- class: 동일한 여러개의 값 사용 가능 : element를 그루핑할 때 사용
- attr: id와 class를 제외한 나머지 속성들
- Text: 시작태그와 끝태그 사이에 있는 문자열
HTML 구조
- DOCTYPE: 문서의 종류를 선언하는 태그
- html
- head
- meta: 웹페이지에 대한 정보를 넣음
- title: 웹페이지의 제목 정보를 넣음
- body: 화면을 구성하는 엘리먼트가 옴
<!-- HTML 웹문서의 기본적인 구조 --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <title></title> </head> <body> </body> </html>HTML 태그
- html에서 문자를 나타내는 태그
head
- title을 나타낼 때 사용, Head는 총 6가지 종류의 태그가 있음, 숫자가 커질수록 문자의 크기가 줄어듦
%%html <h1>Data1</h1> #제목을 사용할 때 h태그 사용 h1 > h3 문자 크기 작아짐p
- 한 줄의 문자열을 출력하기 위한 태그
%%html <p>data1</p> <p>data2</p>span
- 한 블럭의 문자열을 표현하기 위한 태그
%%html <span>data1</span> <span>data2</span>문자 이외의 HTML 태그
div
- 레이아웃을 나타내는 태그
%%html <div> <p>data1</p> <p>data2</p> </div> <div>data3</div> <div>data3</div>ul, li
- 리스트를 나타내는 태그
%%html <ul> <li>data1</li> <li>data2</li> </ul>a
- 링크를 나타내는 태그, href 속성에 url을 넣음, url과 상대경로를 모두 사용 가능, target='blank' 옵션
# 타겟이 없으면 -> 현재 페이지가 KT 페이지로 바뀜, 기존 페이지는 사라짐! # 타겟을 넣으면 기존 페이지가 열려있는 상태로 새로 KT 페이지가 뜸! %%html <a href = '링크' target='blank'>'문자열'</a>image
- 이미지를 나타내는 태그
# 텍스트가 없으면 엘리먼트에 끝태그가 없어도 됨 %%html <img src='이미지 링크' alt='kt'>
CSS Selector
Element Selector
- 엘리먼트를 이용해 선택할 때 사용
- css selector로 div를 사용하면 가장 위에 있는 dss1 이 선택됨!

ID Selector
- 아이디를 이용해 선택할 때 사용
- 아이디를 셀렉할 때는 #(아이디 이름)으로 선택, css selector #ds2를 사용하면 dds2가 선택
- 여러개를 셀렉할 때는 ,로 구분
- css selector로 #ds2, #ds3를 사용하면 dds2와 dds3가 선택

Class Selector
- 클래스를 이용해 선택할 때 사용, 클래스를 셀렉할 때는 .(클래스 이름)으로 선택
- 아이디를 셀렉할 때는 #(아이디 이름)으로 선택, css selector #ds2를 사용하면 dds2가 선택

Not Selector
- 셀렉터로 엘리먼트를 하나만 제거하고 싶을 때 사용
- not을 사용해 셀렉할 때에는 :not(선택에서 제거하고 싶은 셀렉터)으로 선택
- 아래에서 .ds:not(.ds2)로 셀렉하면 class가 ds2인 클래스를 제외하고 나머지 ds1, ds3, ds4, ds5가 선택

nth-child Selector
- 엘리먼트로 감싸져있는 n번째 엘리먼트가 설정한 셀렉터와 일치하면 선택
- .ds:nth-child(3), .ds:nth-child(4)로 설정하면 ds4, ds5가 선택
- nth-child의 ()안의 숫자는 가장 첫번째가 0이 아니라 1로 시작

모든 하위 depth(공백) Selector
- 공백문자로 하위 엘리먼트를 셀렉트했을 때, 모든 하위 엘리먼트를 선택
- .contants h1를 선택하면 inner_1, inner_2가 선택

바로 아래 depth(>) Selector
- > 문자로 하위 엘리먼트를 셀렉트 했을때, 바로 아래 엘리먼트를 선택
- .contants > h1를 선택하면 inner_1이 선택

네이버 연관 검색어 수집 실습
import pandas as pd import requests from bs4 import BeautifulSoup #css-selector로 엘리먼트 선택 가능 query = '검색어' url = f'https://search.naver.com/search.naver?query={query}' # request(URL) > response:str(html) response = requests.get(url) #str(html) > bs object dom = BeautifulSoup(response.text, 'html.parser') # bs object > .select(css-selector), select_one(css-selector) > str(text) selector = '개발자도구에서 copy한 css-selector' elements = dom.select(selector) len(elements), elements[0] keywords = [element.text.strip() for element in elements]'KT 에이블스쿨 복습' 카테고리의 다른 글