-
[0419 복습] 딥러닝_언어 모델 활용_transformer (GPT, BERT)KT 에이블스쿨 복습 2024. 4. 20. 10:11
**셀프 복습용으로 작성한 것이라 실수가 있을 수 있습니다!
혹시 실수를 발견하시면 댓글로 알려주시면 감사드리겠습니다 :)
딥러닝 심화2
CH1. ChatGPT API로 연결하기
API
- 클라이언트 프로그램에게 요청을 받아 서버를 전달, 서버를 요청 처리한 후 결과 데이터를 API에 전달

- API를 사용하기 위해서 API 뒷부분(Backend)을 잘 몰라도 Request와 Response만 알면 사용 가능
- Request: API 주소 + API Key, Request 형식: 요청 양식
- Response: Response 형식: 결과 양식
사용하기
!pip install openai import pandas as pd import numpy as np import openai from openai import OpenAI api_key = '고유한 키 값' # 채팅을 위한 함수 생성 def ask_chatgpt1(question): client = OpenAI(api_key = api_key) response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": question}, ] ) return response.choices[0].message.content question = "질문?" response = ask_chatgpt1(question) print(response)CH2. PandasAI로 데이터 탐색 및 분석하기
PandasAI란
- 생성 AI를 사용해 데이터 전처리 및 탐색 및 분석 가능
- 특징
- 자연어 쿼리: 자연어로 데이터에 질의
- 데이터 시각화: 그래프와 차트를 생성해 데이터를 시각화
- 데이터 정리: 누락된 값을 해결해 데이터 세트를 정리
- 특징 생성: 특징 생성을 통해 데이터 품질을 향상
- 데이터 커넥터: CSV, XLSX, PostgreSQL, MySQL, GigQuery, Databrick, Snowflake 등과 같은 다양한 데이터 소스 지원
사용하기
!pip install pandasai import pandas as pd import numpy as np from pandasai import SmartDataframe from pandasai.llm import OpenAI api_key = '고유한 키 값' # 데이터 프레임 만들기 sales_by_country = pd.DataFrame({ "country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"], "sales": [5000, 3200, 2900, 4100, 2300, 2100, 2500, 2600, 4500, 7000] }) sales_by_country # 거대모델 불러오기 llm = OpenAI(api_token=api_key) # 스마트 데이터프레임으로 변환 df = SmartDataframe(sales_by_country, config={"llm": llm}) # 질문 query = '질문?' df.chat(query)여러 데이터 프레임을 묶어서 분석하기
- SmartDatalake 생성 → pd.merge와 같은 기능 (데이터 프레임 만들 때 칼럼 이름 같게 만들어야 함!
# 데이터 프레임 만들기까지는 똑같음 llm = OpenAI(api_token=api_key) sdl = SmartDatalake([df1, df2], config={"llm": llm}) # merge sdl.chat("질문?")CH3. 언어모델 이해
NLP (Natural Language Processing)
- NLP: 인간 언어와 관련된 모든 것을 이해하는 데 초점을 맞춘 언어학 및 기계 학습 분야
- NLP의 작업 목표: 단일 단어를 개별적으로 이해하는 것뿐만 아니라 해당 단어의 맥락을 이해하는 것
- 일반적인 NLP 작업
- 문장 분류: 리뷰이ㅡ 감정 파악, 이메일 스팸 여부 감지 등
- 개체 명(사람, 위치, 조직 등) 인식
- 문장 생성
- 질문에 대한 답변 (ex.GPT)
- 텍스트 번역, 요약
Transformer
- 기존의 NLP: RNN 기반
→ 오랫동안 언어모델을 위한 주요한 접근 방식 - 단점: 병렬 처리 어려움, 장기 의존성 문제, 확장성 제한
- Transformer 등장
- RNN 모델의 단점을 극복
- 언어 모델의 Game Changer → 덕분에 LLM이 발전하게 됨
- Transformer의 특징
- 이전 문장들을 잘 기억 (Attention, Attention score)
- 문맥상 집중해야 할 단어를 잘 캐치 (문장이나 단어 사이의 관계를 파악하는 데 탁월함)
Transformer 사용하기
- pipeline 함수
- transformer 기반 LLM 모델을 손쉽게 사용할 수 있게 해주는 함수
- 복잡한 언어 모델 처리(NLP) 과정을 감추고, 다음 과정이 물 흐르듯 흘러가게 해줌!
- 사용자 입력(text)을 받아 → Text를 모델이 이해 가능한 형태로 전처리 → 모델에 전달, 예측
→ 측 결과를 사람이 이해 가능한 형태로 후처리 & return
- pipeline으로 사용 가능한 언어 관련 task
- sentiment-analysis: 주어진 문장에 대해 긍정, 부정 분류
- zero-shot-classification: 학습 과정에서 본 적 없는 클래스에 대해 분류
- summarization: 긴 문장이나 글에 대해 핵심 내용을 짧게 요약하는 기술
- translation: 다양한 언어로 번역
- text-generation: 몇 글자를 적어서 입력하면, 이어서 문장을 생성하는 기술
- feature-extraction
- fill-mask
- ner(개체 명 인식)
- question-answering
# colab에서는 이미 설치되어 있음 !pip install transformers from transformers import pipeline classifier = pipeline(task = "sentiment-analysis", model = 'bert-base-multilingual-cased') classifier = pipeline("sentiment-analysis") # 모델 사용 text = ["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!", "I have a dream.", "She was so happy."] classifier(text)Hugging Face
- 허깅 페이스
- 자연어 처리(NLP) 및 인공지능(AI) 분야에서 가장 인기 있는 오픈 소스 라이브러리와 모델을 제공하는 플랫폼
- 허깅 페이스의 기여
- transformer 라이브러리 제공: 사전 훈련된 다양한 Transformer 기반 LLM 모델을 쉽게 사용, 텍스트 분류 질문 답변 등 다양한 NLP 태스크를 수행
- 모델 허브 제공: 연구자와 개발자가 자신의 모델 공유, 다른 사람들의 모델을 탐색하고 사용할 수 있는 플랫폼 제공, 커뮤니티에 의해 지속적으로 확장
언어 모델링 절차
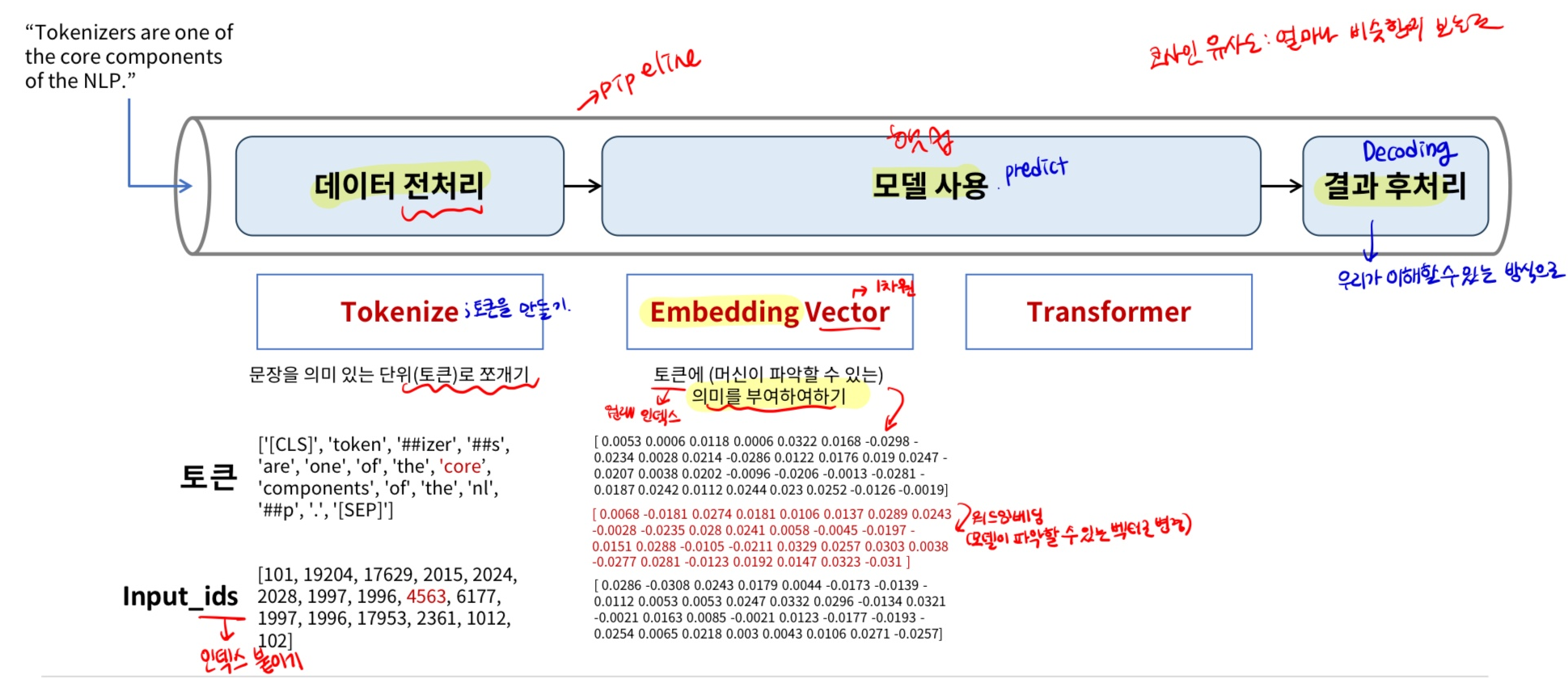
데이터 전처리: Tokenize(토큰화)
- 토큰화: 문장을 분석하기 위한 최소 단위 데이터(토큰)로 변화시키는 것 → 사람이 결정하는 하이퍼 파라미터
- 문자 토큰화: 문자 단위
- 단어 토큰화: 단어 단위
- 형태소 토큰화: 형태소 단위
# 모델, 토크나이저 다운 from transformers import PreTrainedTokenizerFast, BartForConditionalGeneration tokenizer = PreTrainedTokenizerFast.from_pretrained("ainize/kobart-news") model = BartForConditionalGeneration.from_pretrained("ainize/kobart-news") # 입력 데이터 전처리(토크나이즈) input_text = ''' 국내 어쩌구 저쩌구 식으로 입력할 문장을 넣어줘용 ''' # 토크나이즈(encoding) input_ids = tokenizer.encode(input_text, return_tensors="pt") # 입력 토큰, 모델은 사전이 있어야 함 (사전에서 찾아보기) input_ids # 모델 사용 # 모델 사용 summary_text_ids = model.generate( input_ids=input_ids, # 입력으로 받는 데이터의 토큰 bos_token_id=model.config.bos_token_id, # Begin of String 문장이나 문단 등의 시작을 나타내는 특수한 토큰 ID eos_token_id=model.config.eos_token_id, # End of String 문장이나 문단 등의 종료 나타내는 특수한 토큰 ID length_penalty=2.0, # 생성된 텍스트의 길이에 대한 패널티. 1< 더 긴 문장을 생성하려는 경향, 1 > 더 짧은 문장을 선호 max_length=50, # 생성될 수 있는 최대 텍스트 길이(토큰 수) min_length=30, num_beams=4 # 빔 서치는 텍스트 생성 시 여러 가능성 있는 출력 중 최적의 결과를 찾기 위해 사용되는 기법. 이 클수록 더 많은 가능성을 탐색 ) # 출력 토큰을 문장으로 변환(Decoding) print(tokenizer.decode(summary_text_ids[0], skip_special_tokens=True)), 결과 후 처리Embedding(임베딩)
- 임베딩: 사람이 쓰는 자연어(단어나 문장)를 machine이 이해할 수 있는 숫자의 나열(벡터)로 변환
- 사람의 언어인 자연어를 처리하게 하려면 자연어를 숫자로 바꿔 입력해줘야 함
- 단어 임베딩
- 단어를 고차원 벡터로 매핑하는 기술
- 문서, 문장 내에서 단어의 의미와 문맥을 담아 냄
- Word2Vex, FastText 등
!pip install gensim from gensim.models import Word2Vec # 각 문장 토크나이즈 token_sent = [tokenizer.convert_ids_to_tokens(tokenizer(text).input_ids) for text in text_data] token_sent[0] # Word2Vec 임베딩 생성 model = Word2Vec(sentences=token_sent, vector_size=30, window=5, min_count=1, workers=4) # 토큰 'core'의 벡터 확인 token = 'components' vector = model.wv[token] print('index :', tokenizer([token])) print('embedding vector : \n', vector.round(4))CH4. 언어모델 Fine-tuning
Fine-tuning
- Fine-tuning이란
- 사전 훈련된 모델을 특정 작업이나 데이터셋에 맞게 미세 조정하는 과정
Fine-tuning 수행 절차

예제 시나리오 - ① 사전 학습된 모델
- DistilBERT 모델선정
- BERT 모델은 언어 이해, 맥락 파악 good, 그러나 BERT의 복잡성과 크기는 특히 자원이 제한된 환경에서의 사용이 어려움
- DistillBERT (경량화 모델)
→ BERT의 크기와 복잡성을 줄이면서도 성능의 상당 부분을 유지한 경량화 모델 - BERT의 파라미터 수 40% 감소 → 학습 및 예측 속도 60% 향상
- BERT의 97% 성능 유지
예제 시나리오 - ② 데이터 준비
- 트랜스포머 모델이 요구하는 입력 데이터의 형식
- input_ids: 토큰화된 입력 시퀀스를 숫자 ID로 변환한 것
- attention_mask: 모델이 패딩된 부분을 무시하고 실제 유용한 데이터에만 집중할 수 있도록 함
- 패딩(padding): 토큰의 길이를 맞추기 위해서, 짧은 문장은 0으로 채움
- tensorflow 모델에 입력하기 위한 dataset으로 변환(.to_tf_dataset)
- 토큰화 데이터셋을 모델 입력에 필요한 feature와 target(label) 추출
- 텐서플로우 데이터셋 객체(tf.data.Dataset)로 변환
예제 시나리오 - ③ 모델 수정
- DistilBERT 모델에 출력 레이어의 노드를 지정
- TFAutoModelForSequenceClassification
- TF: 텐서플로우 용
- AutoModel: 사전 훈련된 모델의 이름이나 경로 제공 → 적절한 모델 아키텍처와 가중치를 자동으로 로드
- SequenceClassification: 시퀀스 분류, 다중 분류와 유사 (예: 텍스트 분류, 감정 분석 등)
- 주요 특징
- 유연성: 다양한 프랜스포머 기반 모델 지원(BERT, RoBERTa, ElECTRA, DistilBERT 등)
- 용이성: 복잡한 모델 아키텍처에 대한 깊은 이해 없이도 고성능의 자연어 처리 모델을 빠르게 구현하고 실험 가능
파인 튜닝: 사전 훈련된 모델을 자신의 데이터셋에 맞게 파인 튜닝 가능
예제 시나리오 - ④ 추가 학습
- 작은 학습률 지정
- 이미 학습된 파라미터가 있는 상황에서 추가 학습하며 미세 조정하는 것이므로, 일반적으로 학습률은 작게 둠
- 데이터 크기, epochs
- 시스템 환경에 맞게, 소요 시간, 성능을 고려하여 조정
- 예측 및 성능 평가
- 일반적인 다중 분류 모델 평가와 동일
'KT 에이블스쿨 복습' 카테고리의 다른 글
